
Show code cell source
import os
# Por precaución, cambiamos el directorio activo de Python a aquel que contenga este notebook
if "PAD-book" in os.listdir():
os.chdir(r"PAD-book/Laboratorio-Computacional-de-Analytics/S1 - Bienvenida, estructuras de datos y de control/S1.TU2/")
Estructuras de datos: listas, tuplas, conjuntos y diccionarios#
Al inciar un proyecto de analítica de datos resulta fundamental almacenar información en la máquina con el fin de procesarla de una manera eficiente. Las estructuras de datos resuelven esta necesidad, ya que nos proveen diferentes formas de representar información computacionalmente.
Requisitos#
Para desarrollar este tutorial necesitarás:
Aplicar las funcionalidades básicas de un Jupyter Notebook.
Declarar y utilizar variables.
Objetivos#
Al final de este tutorial podrás:
1. Comprender los usos y características principales de las estructuras de datos más comunes.
2. Declarar estructuras de datos para almacenar información de una manera eficiente.
3. Consultar y modificar la información almacenada en las diferentes estructuras de datos.
4. Conocer métodos y particularidades para cada una de las estructuras de datos más comunes.
1. Listas#
1.1. Usos y características principales#
Una lista permite representar una colección ordenada de cualquier cantidad de elementos. Estos elementos pueden ser números, palabras, otras listas, etc. Una lista es una estructura de datos flexible debido a que no necesariamente todos sus elementos tienen que ser del mismo tipo. Adicionalmente, es mutable debido a que podemos modificar sus elementos.
1.2. Declaración#
Para declarar una lista iniciamos abriendo un corchete ([ ]), escribimos uno a uno sus elementos separados por medio de comas (,) y finalizamos cerrando el corchete. En particular, notemos que es posible declarar listas vacías. A continuación, declaramos de forma general una lista y la almacenamos con el nombre nombre_lista:
nombre_lista = [elemento_1, elemento_2, elemento_3]
Ejemplo 1#
Un agricultor quiere registrar la producción de su cultivo de sandías para los primeros cinco meses del año. Él produjo 25, 30, 15, 16 y 13 sandías en cada uno de estos meses, respectivamente. Para representar está información resulta útil declarar la siguiente lista:
lista_produccion = [25, 30, 15, 16, 13]
lista_produccion
[25, 30, 15, 16, 13]
1.3. Consulta y modificación de elementos#
Consulta#
Los elementos de una lista son almacenados de manera ordenada de acuerdo al orden en que se hayan declarado. Podemos consultar cada uno de ellos utilizando el índice único que Python le asigna con el fin de identificarlo. Es importante tener en cuenta que en Python los índices comienzan en el número 0. Así, el índice 0 se asigna al primer elemento de la lista, el índice 1 al segundo, etc. También, es posible consultarlos utilizando una indexación negativa, en la cual el índice -1 se asigna a la última posición de la lista, el índice -2 a la penúltima, etc. La imagen a continuación ejemplifica estas dos maneras de consultar cada uno de los elementos de la lista nombre_lista que declaramos anteriormente.

Para consultar un elemento de una lista escribimos el nombre de la lista seguido del índice del elemento que queremos consultar entre corchetes. Por ejemplo, para acceder al segundo elemento de la lista nombre_lista escribimos:
nombre_lista[1]
De manera equivalente, utilizando la indexación negativa escribimos:
nombre_lista[-2]
Ejemplo 2#
El mismo agricultor de sandías del Ejemplo 1 desea saber la producción del último mes de su cultivo de sandías. Escribimos la siguiente instrucción para este propósito:
lista_produccion[4]
13
Dado que este es el último elemento de nuestra lista, intentar consultar un índice mayor, que exceda el rango de la lista, nos arrojará un error de tipo IndexError. A continuación mostramos un ejemplo de este.
lista_produccion[5]
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Cell In[4], line 1
----> 1 lista_produccion[5]
IndexError: list index out of range
Modificación#
Como se mencionó anteriormente, una lista es una estructura de datos mutable. Para modificar un elemento, lo consultamos y con un signo igual (=) le asignamos un nuevo valor. Por ejemplo, para modificar el segundo elemento de la lista nombre_lista y asignarle el valor nuevo_valor, escribimos:
nombre_lista[1] = nuevo_valor
Ejemplo 3#
Volvamos a la lista lista_produccion declarada en el Ejemplo 1, la cual registra la producción del cultivo de sandías del agricultor. Requerimos lo siguiente:
Consultar la producción del primer y del tercer mes del año.
Modificar el registro de la producción del último mes puesto que se conoció que realmente fue de 22 sandías.
Resolvamos el primer requerimiento.
print("La producción del primer mes es " + str(lista_produccion[0]))
print("La producción del tercer mes es " + str(lista_produccion[2]))
La producción del primer mes es 25
La producción del tercer mes es 15
Resolvamos el segundo requerimiento teniendo en cuenta que la manera mas intuitiva de hacerlo es utilizando la indexación negativa.
lista_produccion[-1] = 22
print("La lista modificada es: " + str(lista_produccion))
La lista modificada es: [25, 30, 15, 16, 22]
Ahora, resolvamos nuevamente el segundo requerimiento utilizando indexación positiva. Considerando que la función len nos permite conocer el tamaño de una lista, podemos resolverlo como se muestra a continuación:
print("El tamaño de la lista es: " + str(len(lista_produccion)))
lista_produccion[len(lista_produccion) - 1] = 22
print("La lista modificada es: " + str(lista_produccion))
El tamaño de la lista es: 5
La lista modificada es: [25, 30, 15, 16, 22]
1.4. Métodos y particularidades#
Rebanado#
En las estructuras de datos ordenadas como las listas es posible hacer referencia a una porción de los datos. Esto se conoce como rebanado (slicing) y consiste en seleccionar los elementos desde cierto índice inicial hasta cierto índice final, tomando una porción de los datos de alguna estructura de datos y no necesariamente su totalidad.
Pensemos nuevamente en nuestra lista nombre_lista declarada anteriormente. Para aplicar una instrucción de rebanado sobre esta lista elegimos cuáles elementos queremos extraer de la lista original. Supongamos que queremos extraer únicamente los primeros dos elementos. Podemos hacerlo utilizando la siguiente instrucción: nombre_lista[0:2], donde el número ubicado a la izquierda del caracter dos puntos (:) establece desde cuál índice realizamos nuestro rebanado (incluyéndolo), mientras que el número a la derecha establece hasta cuál índice realizamos nuestro rebanado (sin incluirlo). Si no escribimos el número a la izquierda del caracter dos puntos, el rebanado inicia desde el primer elemento. De la misma manera, si no escribimos el número a la derecha del caracter dos puntos, el rebanado finaliza en el último elemento de la lista.
Ejemplo 4#
En la siguiente celda de código encuentras declarada una lista que contiene las 27 letras del abecedario. Basándonos en ella, queremos crear tres listas:
Una lista que contenga las primeras cuatro letras del abecedario.
Una lista que contenga desde la decimosexta letra hasta la última letra del abecedario.
Una lista que contenga desde la tercera letra del abecedario hasta la antepenúltima letra.
lista_abc = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'ñ', 'o', 'p', 'q',
'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
Para crear la primera lista, podemos utilizar cualquiera de las siguientes dos instrucciones:
print(lista_abc[0:4])
print(lista_abc[:4])
['a', 'b', 'c', 'd']
['a', 'b', 'c', 'd']
De forma similar, utilizamos la siguiente instrucción para crear la segunda lista, prescindiendo de especificar el número a la derecha del rebanado.
lista_abc[15:]
['o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
En el rebanado también podemos utilizar la indexación negativa e incluso hacerlo de forma mixta con la indexación positiva. Para esto último debemos tener un especial cuidado, procurando que el elemento asociado al primer índice que se le suministra a la instrucción de rebanado se encuentre antes del elemento asociado al segundo índice suministrado, pues de lo contrario, la instrucción retornaría una lista vacía.
Para crear la tercera lista podemos usar la indexación de forma mixta puesto que tenemos presente que la tercera letra del abecedario ('c') antecede a la antepenúltima ('x').
lista_abc[2:-2]
['c',
'd',
'e',
'f',
'g',
'h',
'i',
'j',
'k',
'l',
'm',
'n',
'ñ',
'o',
'p',
'q',
'r',
's',
't',
'u',
'v',
'w',
'x']
Listas anidadas#
En Python, a una lista que se encuentra contenida dentro de otra se le denomina una lista anidada. De esta manera, podemos tener listas que contengan una o más listas con el fin de tener agrupaciones que tengan un sentido dentro del contexto de nuestro problema. Su declaración general sería así:
lista_anidada = [elemento_1, elemento_2, elemento_3]
lista_contenedora = [elemento_4, lista_anidada, elemento_5, elemento_6]
Ejemplo 5#
Se nos solicita que declaremos una lista que contenga los números del 0 al 9, diferenciando los números naturales del cero.
lista_nums_naturales = [1,2,3,4,5,6,7,8,9]
lista_nums_del_0_al_9 = [0, lista_nums_naturales]
lista_nums_del_0_al_9
[0, [1, 2, 3, 4, 5, 6, 7, 8, 9]]
Esta declaración también la habríamos podido realizar elemento a elemento.
lista_nums_del_0_al_9_opcion_2 = [0,[1,2,3,4,5,6,7,8,9]]
lista_nums_del_0_al_9_opcion_2
[0, [1, 2, 3, 4, 5, 6, 7, 8, 9]]
Consulta y modificación de elementos dentro de una lista anidada.#
Para consultar o modificar un elemento dentro de una lista anidada, también utilizamos los corchetes que empleábamos al consultar un elemento de una lista convencional; esta vez debemos hacerlo recursivamente. Para ejemplificar esto, recordemos las listas lista_anidada y lista_contenedora declaradas anteriormente.
El primer paso consiste en consultar el índice que le corresponde a la lista anidada dentro de la lista que la contiene; en este caso el índice 1 de la lista lista_contenedora.
lista_contenedora[1]
Una vez consultada la lista, consultamos dentro de la lista anidada el índice corresponidente al elemento de interés. Por ejemplo, para consultar el primer elemento de la lista lista_anidada escribimos:
lista_contenedora[1][0]
Para modificarlo, asignamos un nuevo valor con un signo igual (=) tal y como se hace con las listas convencionales.
lista_contenedora[1][0] = nuevo_valor
Ejemplo 6#
Un periódico local sostiene sus operaciones principalmente con la publicidad que se encuentra en su página web y con las donaciones que recibe durante sus transmisiones en vivo, las cuales suelen durar tres horas. En la hora 1 únicamente recibieron dos donaciones de un dólar, en la hora 2 cinco donaciones de tres dólares, y en la hora 3 cuatro donaciones de siete dólares. La lista se encuentra declarada en la siguiente celda.
lista_donaciones = [[1, 1], [3, 3, 3, 3, 3], [7, 7, 7, 7]]
Más tarde se percataron de que la primera donación del día en realidad había sido de cinco dólares. Se nos solicita modificar la lista para corregir ese error de registro.
lista_donaciones[0][0] = 5
lista_donaciones
[[5, 1], [3, 3, 3, 3, 3], [7, 7, 7, 7]]
Operaciones con listas#
En Python es posible utilizar el operador de suma (+) y el de multiplicación (*) para concatenar y repetir las listas, respectivamente. Si tenemos dos listas y ubicamos el operador de suma en medio de las dos, la lista resultante tendrá todos los elementos de ambas listas.
lista_1 = [elemento_1_lista_1, elemento_2_lista_1, elemento_3_lista_1]
lista_2 = [elemento_1_lista_2, elemento_2_lista_2, elemento_3_lista_2]
lista_3 = lista_1 + lista_2
En este caso lista_3 tendrá 3+3 elementos, donde los elementos de la lista lista_2 serán posicionados justo después de los elementos de la lista lista_1. Así, la lista lista_3 tendrá los siguientes elementos:
lista_3 = [elemento_1_lista_1, elemento_2_lista_1, elemento_3_lista_1, elemento_1_lista_2,
elemento_2_lista_2, elemento_3_lista_2]
Por su parte, el operador de multiplicación permite repetir una lista las veces que se considere necesario. De forma genérica:
lista_4 = [elemento_1, elemento_2] * 3
La lista 4 tendría los siguientes elementos:
lista_4 = [elemento_1, elemento_2, elemento_1, elemento_2, elemento_1, elemento_2]
Ejemplo 7#
En la siguiente transmisión que realizó el periódico del Ejemplo 6, en la hora 1 se registraron cinco donaciones de un dólar, en la hora 2 tres donaciones de nueve dólares, y en la hora 3 solo una donación de dos dólares. Se nos solicita que creemos esta lista usando los operadores de concatenación (+) y repetición (*). Ahora, el periodico nos indicó que ya no es necesario que las listas se encuentren anidadas por horas.
lista_donaciones_2 = [1] * 5 + [9] * 3 + [2]
lista_donaciones_2
[1, 1, 1, 1, 1, 9, 9, 9, 2]
Métodos de las listas#
Las listas cuentan con métodos base, los cuales nos permiten realizar diversas operaciones. Los métodos pueden retornar una nueva lista, modificar la original, o retornar un valor de interés. La siguiente tabla contiene algunos de los métodos de las listas y su descripción.
|
Ordena ascendentemente una lista numérica |
|
Agrega el elemento |
|
Inserta el elemento |
|
Concatena la lista actual con la lista |
|
Remueve el primer elemento de la lista que sea igual a |
|
Remueve el elemento en la posición |
|
Devuelve el índice del primer elemento igual a |
|
Cuenta el número de veces que el elemento |
|
Invierte los elementos de la lista |
|
Devuelve una copia de la lista |
Ejemplo 8#
Seguimos con el periodico del Ejemplo 6. Esta vez, el área de tesorería está interesada en obtener algunos indicadores sobre una lista que unifique las donaciones recibidas en sus dos últimas transmisiones. En particular nos solicita lo siguiente:
Unir ambas listas (
lista_donacionesylista_donaciones_2).Agregar una donación de 3 dólares que olvidaron registrar en la última transmisión.
Obtener el número de donaciones de un dólar que recibió el periódico.
Encontrar la donación más alta que recibió el periódico.
Antes de cumplir con el primer requerimiento, recordemos que que ya no es necesario que las listas se encuentren anidadas por horas y que en la lista lista_donaciones las donaciones aún se encuentran así. Solucionemos esto de la siguiente manera:
lista_donaciones = lista_donaciones[0] + lista_donaciones[1] + lista_donaciones[2]
lista_donaciones
[5, 1, 3, 3, 3, 3, 3, 7, 7, 7, 7]
Para cumplir con el primer requerimiento, utilizamos el método extend, el cual permite ingresar como parámetro una segunda lista para anexarla a la primera. Recuerda que esta operación también se puede hacer con el operador de concatenación (+).
lista_donaciones.extend(lista_donaciones_2)
lista_donaciones
[5, 1, 3, 3, 3, 3, 3, 7, 7, 7, 7, 1, 1, 1, 1, 1, 9, 9, 9, 2]
Para añadir un único elemento al final de la lista, el método más práctico es append.
lista_donaciones.append(3)
lista_donaciones
[5, 1, 3, 3, 3, 3, 3, 7, 7, 7, 7, 1, 1, 1, 1, 1, 9, 9, 9, 2, 3]
Para contar el número de donaciones de un dólar, lo más práctico es utilizar el método count, ingresando como parámetro el número a contar.
lista_donaciones.count(1)
6
Para encontrar la donación más alta tenemos dos aproximaciones. La primera consiste en ordenar la lista (ascendentemente) con el método sort y consultar el último elemento.
lista_donaciones.sort()
lista_donaciones[-1]
9
La segunda aproximación consiste en utilizar la función max de Python.
max(lista_donaciones)
9
2. Tuplas#
2.1. Usos y características principales#
Las tuplas son otra estructura de datos ordenada que, al igual que las listas, pueden guardar diferentes tipos de datos o incluso elementos repetidos. No obstante, la principal diferencia es que son inmutables; esto significa que no se podemos añadir, alterar, ni eliminar elementos.
Diferencias y similitudes entre tuplas y listas#
Diferencias:
No podemos agregar ni eliminar elementos a una tupla.
No podemos modificar el orden de una tupla.
No podemos modificar el valor de un elemento perteneciente a una tupla.
Similitudes:
Podemos crear tuplas vacías. Aunque, como se mencionó anteriormente, ya no podrán ser rellenadas.
La función
lennos sirve para conocer su tamaño.Al ser estructuras ordenadas, podemos realizar rebanados.
Disponemos de los métodos expuestos en la tabla de métodos de las listas, desde que no impliquen mutar una tupla. Por ejemplo:
index,count,copy.
2.2. Declaración#
Para declarar una tupla empleamos paréntesis (()) y separamos los elementos contenidos por medio de comas, como se muestra a continuación:
nombre_tupla = (elemento_1, elemento_2, elemento_3)
También es una práctica común prescindir de los paréntesis:
nombre_tupla = elemento_1, elemento_2, elemento_3
Ejemplo 9#
Para un proyecto se quiere realizar un pronóstico de la posición que ocupará cada país sudamericano en las eliminatorias de Catar 2022. Para ello, registremos en una tupla la tabla de posiciones de las pasadas eliminatorias de Rusia 2018. Eligimos almacenar esta tabla de posiciones en una tupla, ya que no existe una razón para agregar o quitar países, ni para modificar la posición de los países en la tabla.
tupla_eliminatorias_2018 = ("Brasil", "Uruguay", "Argentina", "Colombia", "Perú", "Chile", "Paraguay", "Ecuador", "Bolivia", "Venezuela")
tupla_eliminatorias_2018
('Brasil',
'Uruguay',
'Argentina',
'Colombia',
'Perú',
'Chile',
'Paraguay',
'Ecuador',
'Bolivia',
'Venezuela')
Comprobemos que no es posible modificar una tupla:
try: # Aquí tratamos de
tupla_eliminatorias_2018[2] = "Colombia" # ejecutar esta instrucción.
except: # En caso de que no se pueda ejecutar la instrucción,
print("No es posible cambiar el elemento") # imprimimos lo siguiente.
No es posible cambiar el elemento
2.3. Consulta#
De la misma forma que en las listas, para una tupla de tamaño n, al primer elemento se le asigna el índice 0 y al último el índice n-1. También disponemos de la indexación negativa.

Ejemplo 10#
El líder del proyecto del Ejemplo 9 nos ha solicitado dos tareas:
Conocer los últimos tres países de la tabla de posiciones de las eliminatorias de Rusia 2018.
Consultar la posición que ocupó Colombia en las eliminatorias de Rusia 2018.
Para resolver la primera tarea creemos la siguiente tupla:
tupla_tarea_1 = tupla_eliminatorias_2018[-3:]
tupla_tarea_1
('Ecuador', 'Bolivia', 'Venezuela')
Para resolver la segunda tarea utilizamos el método index.
#Recordemos que la indexación comienza en 0. Por lo tanto, sumamos 1 para conocer la posición de Colombia en la clasificación.
tupla_eliminatorias_2018.index("Colombia") + 1
4
2.4. Métodos y particularidades#
De tuplas a listas y de listas a tuplas#
Pese a que su sintaxis es parecida, una tupla y una lista no se deben confundir, puesto que son dos representaciones del sistema totalmente distintas. Como se mencionó, se diferencian principalmente por su inmutabilidad. Sin embargo, Python establece expresiones que nos permiten crear una lista a través de una tupla, y viceversa. Esto resulta útil si queremos volver inmutable la información contenida en una lista, o cuando tenemos argumentos de peso para modificar la información que antes considerábamos inmutable.
Para generar una lista a partir de una tupla utilizamos la función list de Python.
lista_eliminatorias_2018 = list(tupla_eliminatorias_2018)
lista_eliminatorias_2018
['Brasil',
'Uruguay',
'Argentina',
'Colombia',
'Perú',
'Chile',
'Paraguay',
'Ecuador',
'Bolivia',
'Venezuela']
Por su parte, para generar una tupla a partir de una lista utilizamos la función tuple de Python.
tupla_eliminatorias_2018 = tuple(lista_eliminatorias_2018)
tupla_eliminatorias_2018
('Brasil',
'Uruguay',
'Argentina',
'Colombia',
'Perú',
'Chile',
'Paraguay',
'Ecuador',
'Bolivia',
'Venezuela')
3. Conjuntos#
3.1. Usos y características principales#
Los conjuntos son una estructura de datos que no está indexada y tampoco está ordenada. Pese a que su contenido no puede ser modificado, tampoco son inmutables porque se les pueden añadir elementos. Vistas estas características, es muy difícil pensar un contexto en el que su uso sea preferible a una lista o a una tupla. Sin embargo, resulta necesario conocerlas para familiarizarse con las estructuras no ordenadas.
3.2. Declaración#
Para declarar un conjunto utilizamos unas llaves ({}) y separamos sus elementos con comas. Por ejemplo:
conjunto_1 = {elemento_1, elemento_2, elemento_3}
3.3. Consulta#
De la misma forma que en una lista o en una tupla, los elementos de un conjunto pueden ser de cualquier tipo, un número, una lista, una tupla, una cadena de caracteres, entre otros. Sin embargo, dado que los conjuntos no están indexados, no disponemos de un índice para encontrar un elemento específico de un conjunto, por lo que podemos limitarnos a consultar si un elemento existe dentro de un conjunto utilizando la siguiente sintaxis:
elemento_1 in conjunto_1
Nota: también podemos realizar este tipo de consulta con listas y tuplas.
3.4. Métodos y otras características#
Otra característica ya mencionada es que los conjuntos no son inmutables, por lo que se les puede adicionar elementos con los siguientes dos métodos: add y update. Con add se puede agregar un solo elemento al conjunto; similar al método append de las listas. Por otra parte, el método update cumple con una función similar al método extend de las listas, permitiéndonos agregar múltiples elementos al conjunto; a este método se le ingresa como parámetro una lista, una tupla, u otro conjunto.
Ejemplo 11#
En la siguiente celda vas a encontrar un conjunto con algunas de las principales petroleras a nivel mundial. Se nos solicita lo siguiente:
Consultar si
"Shell"se encuentra en el conjunto.Agregar la compañía
"Exxon Mobil"al conjunto.Incluir simultáneamente a
"Chevron"y a"Halliburton"en el conjunto.
conjunto_petroleras = {"Saudi Aramco", "Shell", "British Petroleum", "Total"}
Para empezar, resolvamos el primer requerimiento.
"Shell" in conjunto_petroleras
True
Para agregar a "Exxon Mobil" utilizamos el método add.
conjunto_petroleras.add("Exxon Mobil")
conjunto_petroleras
{'British Petroleum', 'Exxon Mobil', 'Saudi Aramco', 'Shell', 'Total'}
Finalmente, realicemos la tercera solicitud utilizando el método update.
conjunto_petroleras.update(["Chevron", "Halliburton"])
conjunto_petroleras
{'British Petroleum',
'Chevron',
'Exxon Mobil',
'Halliburton',
'Saudi Aramco',
'Shell',
'Total'}
4. Diccionarios#
4.1. Usos y características principales#
Los diccionarios son estructuras de datos no ordenadas que identifican relaciones de correspondencia entre llaves y valores. Los diccionarios buscan entonces indexar una colección de valores a una colección de llaves.
Llaves:
Pueden ser un número, una cadena de caracteres, una tupla, entre otros.
Son inmutables.
Son un elemento único que se registra en el diccionario. No puede haber dos llaves iguales.
Dos o más llaves pueden tener un mismo valor.
Podemos usar el método
keyspara separarlas de sus valores.
Valores:
Pueden ser cadenas de caracteres, tuplas, listas, otro diccionario, etc.
Podemos usar el método
valuespara separarlos de sus llaves.
4.2. Declaración#
Para declarar un diccionario utilizamos el caracter llave ({ }) y separamos sus elementos por medio de comas. Cada elemento se compone de una llave y un valor, los cuales se separan por dos puntos (:). En este caso, a diferencia de las listas y las tuplas, no importa el orden de los elementos. De forma general, su representación sería la siguiente:
diccionario = {llave_1: valor_1, llave_2: valor_2, llave_3: valor_3}
4.3. Consulta y modificación#
Consulta#
Para consultar un valor específico utilizamos la misma sintaxis de las listas y tuplas, teniendo presente que los índices de un diccionario son sus llaves. A continuación se muestra un ejemplo:
diccionario[llave_1]
Además, al igual que en los conjuntos, podemos consultar si una llave existe en un diccionario como se muestra a continuación:
llave_1 in diccionario
Modificación#
Para modificar el valor asociado a una llave, volvemos a usar el igual asignar el nuevo valor.
diccionario[llave_1] = nuevo_valor
Ejemplo 12#
Un niño le pidió ayuda para crear un diccionario de la edad de su familia. Su mamá y su papá tienen 40 años cada uno, su hermana 8 años y su hermano 11 años. A continuación, se presenta un diagrama con las relaciones de correspondencia:
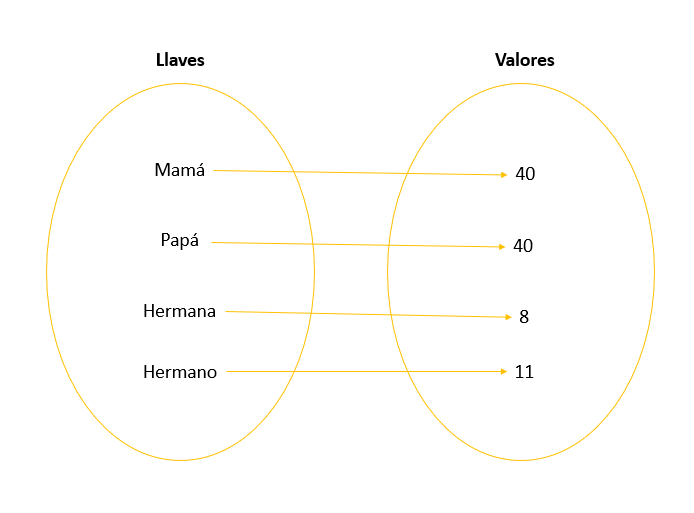
Se nos solicita lo siguiente:
Declarar el diccionario.
Consultar la edad del hermano del niño.
Consultar si la tía está en el diccionario.
Modificar la edad de la hermana que hace poco cumplió 9 años.
Agregar la edad de una tía de 45 años al diccionario.
Primero, usamos la sintaxis definida para declarar un diccionario:
familia = {"Mama": 40, "Papa": 40, "Hermana": 8, "Hermano": 11}
Para consultar la edad del hermano escribimos la siguiente instrucción:
familia["Hermano"]
11
Para consultar si está la tía en el diccionario realizamos lo siguiente:
"Tia" in familia
False
Pese a que las llaves son inmutables, sí se les puede cambiar el valor que tienen asignado. Por lo tanto, es posible cumplir con el cuarto requerimiento como hacemos a continuación:
familia["Hermana"] = 9
Para agregar un nuevo elemento, en este caso la tía de 45 años, utilizamos la misma sintaxis de la modificación.
familia["Tia"] = 45
Ejemplo 13#
Partiendo del diccionario familia declarado en el Ejemplo 12, creemos una lista con sus llaves y otra con sus valores. Por último, necesitamos almacenar ambas listas en una tupla y visualizarla.
Inicialmente podemos separar las llaves de los valores usando el método keys, el cual retorna una estructura de datos predefinida en Python que se llama dict_keys.
llaves = familia.keys()
print(llaves)
type(llaves)
dict_keys(['Mama', 'Papa', 'Hermana', 'Hermano', 'Tia'])
dict_keys
De la misma manera, el método values retorna los valores de un diccionario en un estructura especial de datos, llamada dict_values.
valores = familia.values()
print(valores)
type(valores)
dict_values([40, 40, 9, 11, 45])
dict_values
Para almacenar las llaves y los valores en listas independientes, utilizamos la función list de Pyhton.
lista_llaves = list(llaves)
print("Las llaves del diccionario son: " + str(lista_llaves))
lista_valores = list(valores)
print("Los valores del diccionario son: " + str(lista_valores))
Las llaves del diccionario son: ['Mama', 'Papa', 'Hermana', 'Hermano', 'Tia']
Los valores del diccionario son: [40, 40, 9, 11, 45]
Finalmente, almacenamos ambas listas en una tupla y la visualizamos.
tupla_familia = (lista_llaves, lista_valores)
tupla_familia
(['Mama', 'Papa', 'Hermana', 'Hermano', 'Tia'], [40, 40, 9, 11, 45])
4.4. Métodos y particularidades#
Métodos de los diccionarios#
Al igual que las listas, las tuplas y los conjuntos, los diccionarios disponen de los siguientes métodos:
|
Remueve todos los elementos del diccionario |
|
Retorna una copia del diccionario |
|
Retorna una tupla con las parejas llave-valor |
|
Remueve del diccionario aquellas llaves cuyo valor sea |
|
Concatena el diccionario actual con el diccionario |
|
Retorna el valor asociado a la llave |
|
Retorna un diccionario cuyas llaves son los elementos de |
Ejemplo 14#
Se nos solicita construir un diccionario de tuplas que almacene la tabla de posiciones final de las eliminatorias para los mundiales 2010, 2014 y 2018. Como insumo se tendrán las tuplas de 2010 y 2014 y un diccionario con las de 2018.
tupla_2010 = ("Brasil", "Chile", "Paraguay", "Argentina", "Uruguay", "Ecuador", "Colombia", "Venezuela", "Bolivia", "Perú")
tupla_2014 = ("Argentina", "Colombia", "Chile", "Ecuador", "Uruguay","Venezuela", "Perú", "Bolivia", "Paraguay")
diccionario_2018 = {2018: ("Brasil", "Uruguay", "Argentina", "Colombia", "Perú", "Chile", "Paraguay", "Ecuador", "Bolivia", "Venezuela")}
El procedimiento a seguir consiste en declarar el diccionario con las tuplas de 2010 y 2014 y posteriormente usar el método update para incluir la información del mundial 2018.
diccionarioEliminatorias = {2010: tupla_2010, 2014: tupla_2014}
diccionarioEliminatorias.update(diccionario_2018)
diccionarioEliminatorias
{2010: ('Brasil',
'Chile',
'Paraguay',
'Argentina',
'Uruguay',
'Ecuador',
'Colombia',
'Venezuela',
'Bolivia',
'Perú'),
2014: ('Argentina',
'Colombia',
'Chile',
'Ecuador',
'Uruguay',
'Venezuela',
'Perú',
'Bolivia',
'Paraguay'),
2018: ('Brasil',
'Uruguay',
'Argentina',
'Colombia',
'Perú',
'Chile',
'Paraguay',
'Ecuador',
'Bolivia',
'Venezuela')}
Referencias#
Downey, A., Elkner, J., & Meyers, C. (2012). How To Think Like A Computer Scientist: Learning with Python. Segunda Edición. Disponible en: https://www.openbookproject.net/thinkcs/python/english2e/index.html
Los métodos y definiciones se consultaron en el portal: https://www.w3schools.com/
Créditos#
Autores: Jorge Esteban Camargo Forero, Juan Felipe Rengifo Méndez, Alejandro Mantilla Redondo, Diego Alejandro Cely Gómez
Actualizado por: Jose Fernando Barrera De Plaza
Fecha última actualización: 06/08/2023